Practice 4: Spark MLlib - Logistic Regression
Input Dataset
The main goal of this practice is to learn Logistic Regression Model on the diabets.csv data.
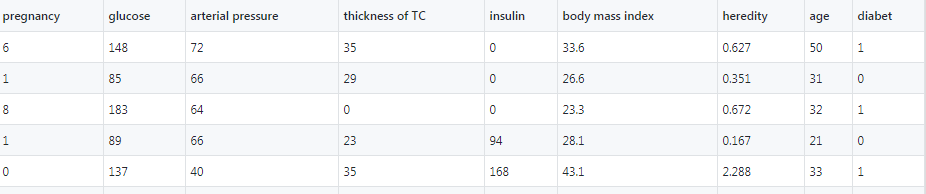
Attribute Information:
- Number of times pregnant
- Plasma glucose concentration a 2 hours in an oral glucose tolerance test
- Diastolic blood pressure (mm Hg)
- Triceps skin fold thickness (mm)
- 2-Hour serum insulin (mu U/ml)
- Body mass index (weight in kg/(height in m)^2)
- Diabetes pedigree function
- Age (years)
- Class variable (0 or 1)
Task
- Load diabets.csv data into Spark's DataFrame and transform features into features are transformed and put into Feature Vectors (by using VectorAssembler)
- Once the set of features defined, split it to the training and testing datasets
- Train Logistic Regression on Training portion of data
- Predict outcome variable (diabet) on Testing dataset
- Test the model