Deploy Zeppelin with Spark and Hadoop on Windows

This tutorial is intended to give an instructions how to install Apache Zeppelin with Apache Spark and HAdoop in Windows Environment.
1) Pre-requisite:
Before installing Zeppelin you have to install and setup:
- Apache Spark
- Apache Hadoop
2) Download Zeppelin
Download and extract Zeppelin from http://zeppelin.apache.org/download.html. Choose version with all supported interpreters.
3) Setup Zeppelin environment
Go to ..\zeppelin\conf and copy the file zeppelin-env.cmd.template with the name _zeppelin-env.cmd. _Here you can set your JAVA_HOME, SPARK_HOME.
set JAVA_HOME=C:/Progra~1/Java/jdk1.8.0_91
set MASTER=spark://192.168.179.1:7077
4) Launch Zeppelin deamon
First of all you have to launch Spark and Hadoop Deamons and to be ensure that they are launched.
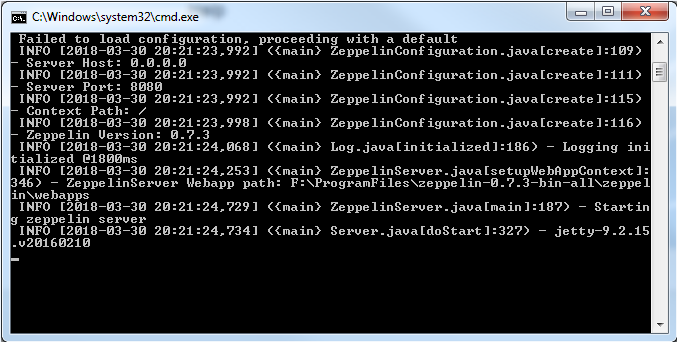
Go to ..\zeppelin\bin _and launch zeppelin.cmd _file
- Wait until Zeppelin server is started
5) Welcome to Zeppelin!
Go to http://localhost:8080 in your web browser -> you should see the following:

6) Check your Spark interpreter
- Create a new Zepeplin note:

- Feed to interpreter a small pieces of spark's code on Scala and run it:
%spark
val a = "hello world"
- If installation is correctly done you should see the following output:
