Apache Spark: SparkSQL and SparkSession
SparkSQL– is a component of the Spark, which supports data requesting by using SQLqueries.
Spark SQL lets you query structured data inside Spark programs using either SQL or theDataFrame API.
The main difference beetween Spark's Core RDD and SparkSQL's RDD (DataFrame) is that DataFrame is structured. Structured data is any data that has a schema — that is, a known set
of fields for each record. When you have this type of data, Spark SQL makes it both easier
and more efficient to load and query.
Therefore, Spark SQL provides three main capabilities:
- It can load data from a variety of structured sources (e.g., JSON, Hive, and Parquet).
- It lets you query the data using SQL, both inside a Spark program and from external tools that connect to Spark SQL through standard database connectors (JDBC/ODBC).
- When used within a Spark program, Spark SQL provides rich integration between SQL and regular Python/Java/Scala code, including the ability to join RDDs and SQL tables, expose custom functions in SQL, and more.
Spark's DataFrame
Spark SQL introduces a tabular data abstraction called DataFrame(in last version Dataset).
A DataFrame is a data abstraction or a domain-specific language (DSL) for working with structured and semi-structured data, i.e. datasets with a schema. A DataFrame is thus a collection of rows with a schema that is a result of a structured query it describes.
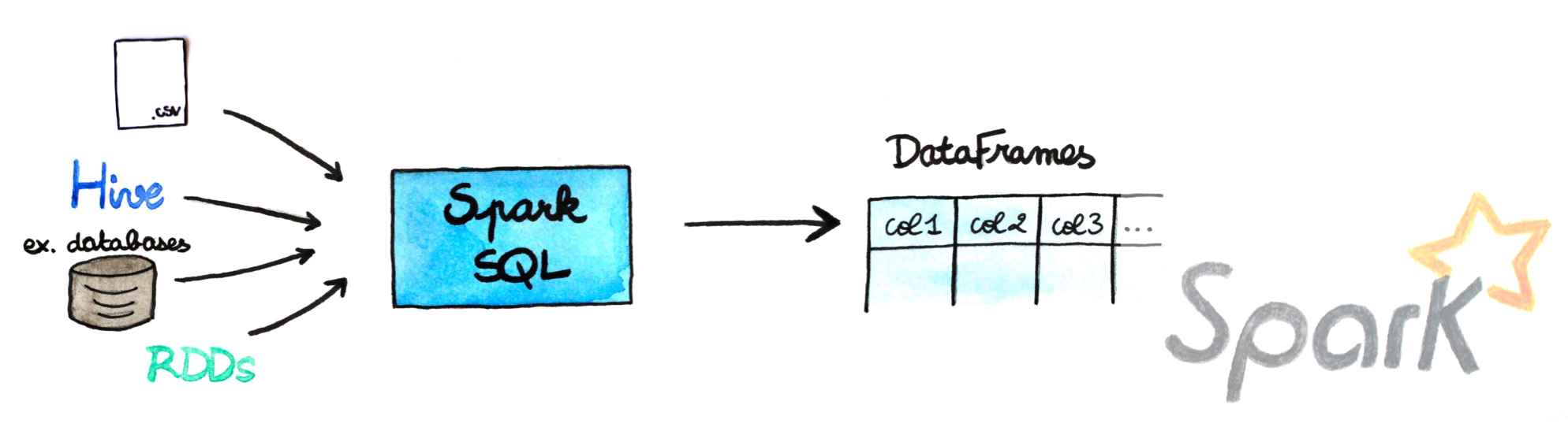
A DataFrame is a distributed collection of data, which is organized into named columns. Conceptually, it is equivalent to relational tables with good optimization techniques. A DataFrame can be constructed from an array of different sources such as Hive tables, Structured Data files, external databases, or existing RDDs.
Spark's SQLContext (Spark version before 2.0)
As it is known SparkContext - is an entry point to your Spark App, by this way Spark's SQLContext - is an entry point to SQL functionality. It is needed to create an instance of SQLContext from a SparkContext. With an SQLContext, you can create a DataFrame from an RDD, a Hive table, or a data source. In previous versions of Spark, you had to create a SparkConf and SparkContext to interact with Spark, as shown here:
a) Create SparkSQL Context
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Dataset, SQLContext}
object SparkSQLExample {
def main(args: Array[String]) {
//Create SparkContext
val conf = new SparkConf()
conf.setAppName("spark-sql-example")
conf.setMaster("local[*]")
conf.set("spark.executor.memory", "1g")
conf.set("spark.driver.memory", "1g")
val sc = new SparkContext(conf)
// Create SQLcontext
val sqlContext = new SQLContext(sc)
// Create the DataFrame
val df = sqlContext.read.json("src/main/resources/cars.json")
// Show the Data
df.show()
}
}
Spark Session in Apache Spark 2.0
Since the Apache Spark 2.0 version the SQLContext was replaced by SparkSession class.
Spark Session - is an entry point to programming Spark with the Dataset and DataFrame API.
Here you can find SparkSession API's. SparkSession explicitly creates SparkConf, SparkContext or SQLContext, as they’re encapsulated within the SparkSession. Using a builder design pattern, it instantiates a SparkSession object if one does not already exist, along with its associated underlying contexts.
The code listed below reads simple file json to DF and print it:
The input file: persons.json
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Dataset, SQLContext, SparkSession}
object SparkSessionExample {
def main(args: Array[String]): Unit = {
val jsonFile = args(0);
//Initialize SparkSession
val sparkSession = SparkSession
.builder()
.appName("spark-sql-basic")
.master("local[*]")
.getOrCreate()
//Read json file to DF
val persons = sparkSession.read.json(jsonFile)
//Show the first 100 rows
persons.show(100);
//Show thw scheme of DF
persons.printSchema();
}
}
As a result we got the DataFrame which is printed below:
