Apache Spark: RDD Transformations
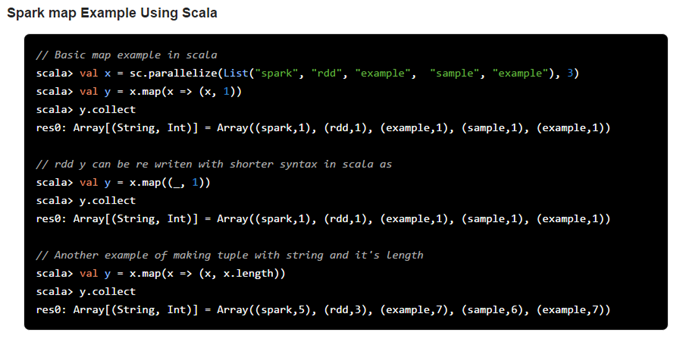
1) map
Spark RDD map function returns a new RDD by applying a function to all elements of source RDD.
Spark map itself is a transformation function which accepts a function as an argument. This function will be applied to the source RDD and eventually each elements of the source RDD and will create a new RDD as a resulting values. Let’s have a look at following image to understand it better

As you can see in above image RDD[String] is the source RDD and RDD[(String,Int)] is a resulting RDD. If we recall our word count example in Spark, RDD[String] has the distributed array of the words, with the map transformation we are mapping each element with integer 1 and creating a tuple like (word, 1).
2) flatMap
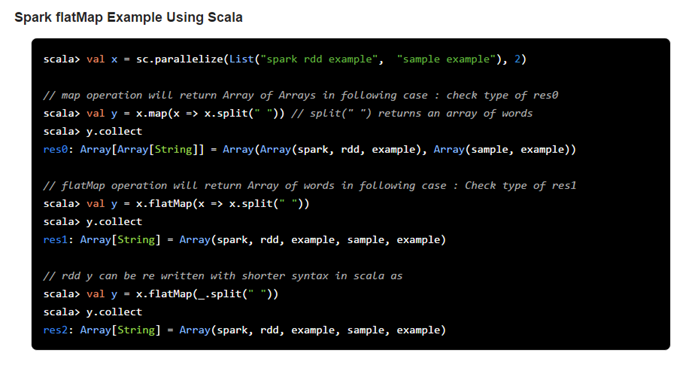
Spark RDD flatMap function returns a new RDD by first applying a function to all elements of this RDD, and then flattening the result.
Spark flatMap is a transformation operation of RDD which accepts a function as an argument. Same as flatMap, this function will be applied to the source RDD and eventually each elements of the source RDD and will create a new RDD as a resulting values. One step more than RDD map operation, it accepts the argument function which returns array, list or sequence of elements instead of a single element. As a final result it flattens all the elements of the resulting RDD in case individual elements are in form of list, array, sequence or any such collection. Let’s check it’s behavior from following image.
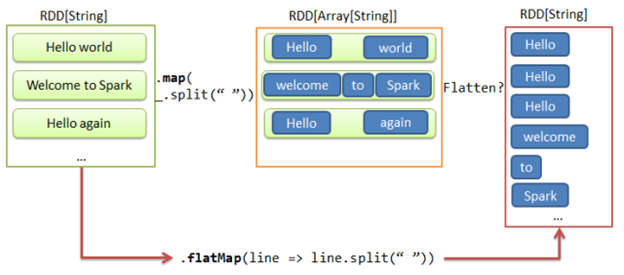
As you can see in above image RDD X is the source RDD and RDD Y is a resulting RDD. As per our typical word count example in Spark, RDD X is made up of individual lines/sentences which is distributed in various partitions, with the flatMap transformation we are extracting separate array of words from sentence. But instead of array flatMap function will return the RDD with individual words rather than RDD with array of words
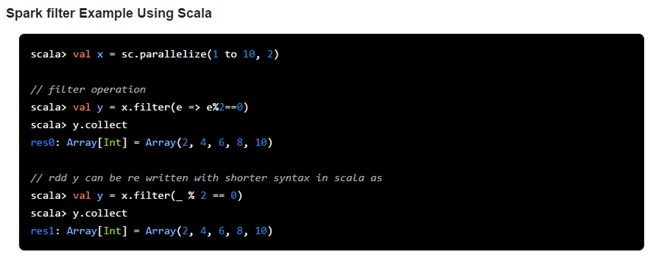
3) filter
Spark RDD filter function returns a new RDD containing only the elements that satisfy a predicate.
As we know, spark filter is a transformation operation of RDD which accepts a predicate as an argument. Predicate is function, which accepts some parameter and returns boolean value true or false. Spark filter method will pass this predicate in argument and operates on the source RDD. It will filter all the elements of the source RDD for which predicate is not satisfied and creates new RDD with the elements, which are passed by the predicate function.
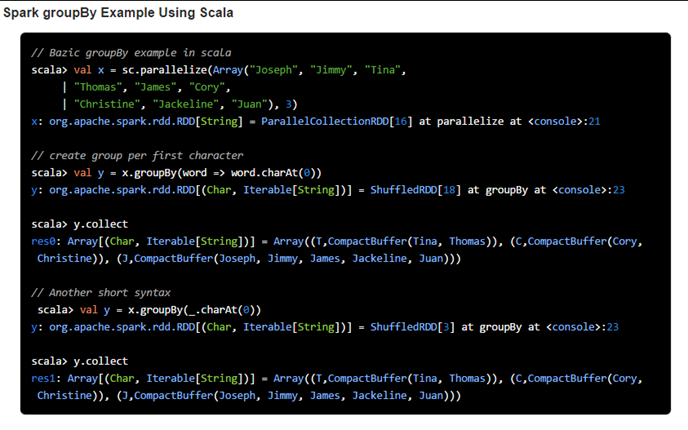
4) groupBy
Spark RDD groupBy function returns an RDD of grouped items.
Spark groupBy function is defined in RDD class of spark. It is a transformation operation which means it is lazily evaluated. We need to pass one function (which defines a group for an element) which will be applied to the source RDD and will create a new RDD as with the individual groups and the list of items in that group. This operation is a wide operation as data shuffling may happen across the partitions.
This operation will return the new RDD which basically is made up with a KEY (which is a group) and list of items of that group (in a form of Iterator). Order of element within the group may not same when you apply the same operation on the same RDD over and over. Additionally, this operation considered to be very costly when you are trying to perform some aggregation on grouped items.