Deploy Spark Cluster on Windows OS

1) Install JAVA SDK
1.1. Download Java SDK from the link
1.2. Set environmental variables.
Do: My computer -> Properties-> Advance system settings -> Advanced -> Environmental variables
User variable:
Variable: JAVA_HOME
Value: C:\Progra~1\Java\jdk1.8.0_121
System variable:
Variable: PATH
Value: C:\Progra~1\Java\jdk1.8.0_121\b
1.3. Check on cmd, see below: java -version
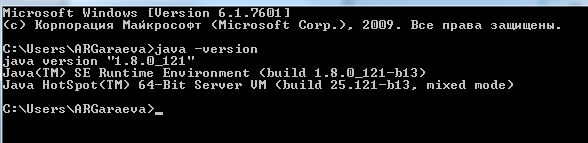
2) Install Apache Spark
Download Apache Sparkfrom the original source
Put extracted Hadoop files into C drive: C:/spark
Set environmental variables for SPARK:
User variables:
Variable: SPARK_HOME
Value: C:\spark
System variables:
Variable: PATH
Value: C:/spark/bin
- Check on cmd: input in cmd spark-shell command and you should see the following picture:

3) Spark Cluster Environment Configuration
A) Go to C:\Spark\conf and edit files: slaves.template and master.template
- Put the IP address of master machine into master file
- Put IP addresses of slaves machine into slaves file
For example:

B) In order to launch spark workers create two bat files with the following commands:
master.bat
start %SPARK_HOME%/bin/spark-class org.apache.spark.deploy.master.Master
slaves.bat
start %SPARK_HOME%/bin/spark-class org.apache.spark.deploy.worker.Worker spark://<MasterIP>:7077
Instead of MaserIP please fill the real IP address of your master machine, for example:
start %SPARK_HOME%/bin/spark-class org.apache.spark.deploy.worker.Worker spark://10.8.41.146:7077
5) Launch Spark's Deamons
- Launch master.bat on your master machine and slaves.bat on each slave node
- Check Spark Cluster State:
Go to web browser http://localhost:4040 (in master node) or http://masterIP:4040 (in slaves) in order to check Spark's state, you should see the following picture:
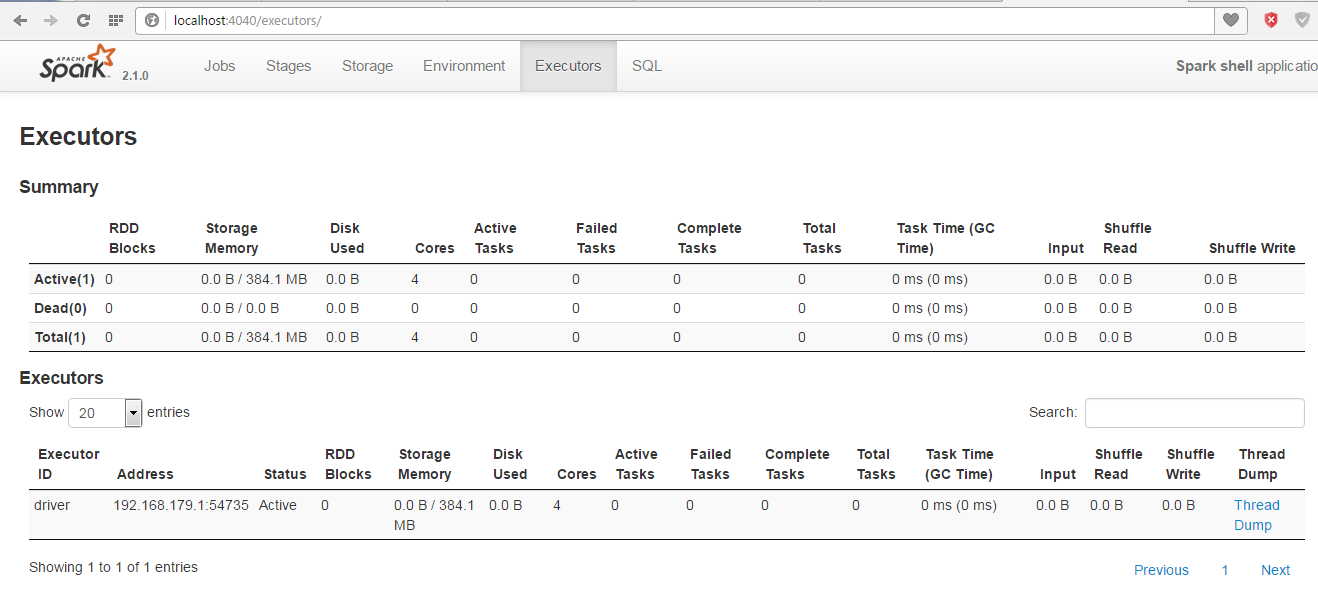 In “Executors” section you should see all nodes of you spark cluster!
In “Executors” section you should see all nodes of you spark cluster!