Apache Spark: Introduction
![]()
Apache Spark is an open-source distributed data processing framework, which provides a fast and flexible platform for parallel data processing. Compared with Apache Hadoop, Apache Spark accelerates the program execution more than 100 times faster in memory, and 10 times faster on disc. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application.
Apache Spark doesn’t provide by it’s own distributed file systems, nevertheless, it perfectly compatible with Hadoop Distributed File System. Therefore, it is common practice to use both Apache Spark and Apache Hadoop: HDFS for storing a huge amount of data and Spark for efficient processing of this data.
Spark is written on Scala and provides API for following programming languages: Java, Scala, Python, R. Spark consist of SparkCore and a number of extensions, such as Spark SQL (allows execution of SQL-queries on the data), Spark Streaming (add-in for processing streaming data), Spark MLlib (set of machine learning libraries), Graphx (designed for distributed processing of graphs). Architecture of Apache Spark is presented in figure presented below.
Apache Spark: Architecture
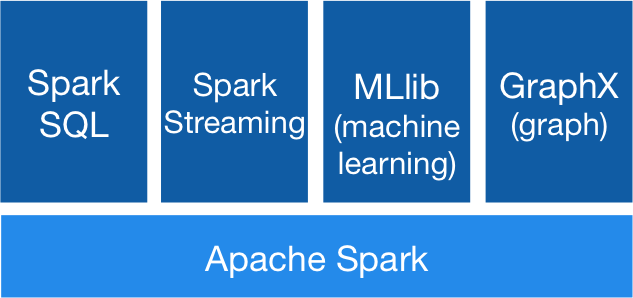
SparkSQL – is a component of the Spark, which supports data requesting by using SQL queries, either by Hive Query Language. Originally, Apache Hive was proposed as a SQL-like tool for data requesting over the Hadoop’s systems. However, now it was adapted to work with Hadoop’s HDFS on the top of the Spark.
Spark Streaming supports the processing of streaming data in real-time; such data could be log files of web servers (eg. Apache Flume, HDFS or Amazon S3), information from social networks, for example, Twitter. The core concept of Spark Streaming component is splitting input real-time stream data into buckets for further processing by Spark engine. Result of processing also is presented as a stream of such buckets.
Spark MLlib is scalable machine learning library, which provides a common machine learning algorithms, such as classification, regression, clustering, collaborative filtering, frequent pattern mining and etc. Spark MLlib focuses on processing data which is presented in RDD, as well as primitive data structures, such vectors and matrices.
Spark GraphX is library for parallel processing of graphs, which extends Spark’s RDD by the new data abstraction – graph and provides a basic functionality to carry out calculations over the graph data structure.