Deploy Hadoop Cluster on Windows OS

1) Install JAVA SDK
1.1. Download Java SDK from the link
1.2. Set environmental variables.
Do: My computer -> Properties-> Advance system settings -> Advanced -> Environmental variables
User variable:
Variable: JAVA_HOME
Value: C:\Progra~1\Java\jdk1.8.0_121
System variable:
Variable: PATH
Value: C:\Progra~1\Java\jdk1.8.0_121\b
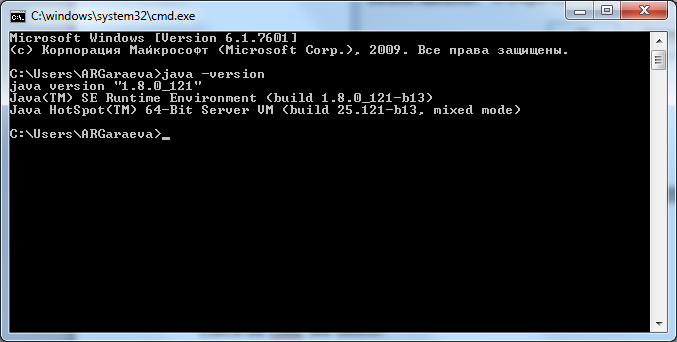
1.3. Check on cmd, see below: java -version
2) Install Apache Hadoop
Download Apache Hadoop from the original source
Put extracted Hadoop files into C drive: C:/Hadoop
Set environmental variables for HADOOP:
User variables:
Variable: HADOOP_HOME
Value: C:\hadoop
System variables:
Variable: PATH
Value: C:/hadoop/bin
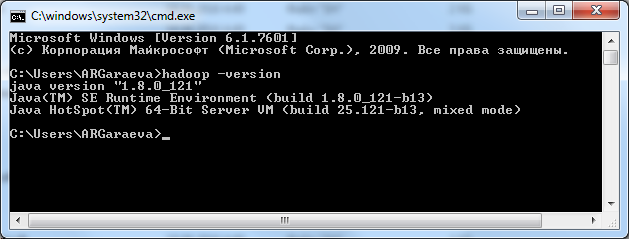
- Check on cmd: hadoop -version
3) Fill up Hadoop's configuration files
- Go to C: Hadoop\etc\hadoop and edit the following files: core-site.xml, hdfs-site.xml, slaves, master:
A) master and slaves files
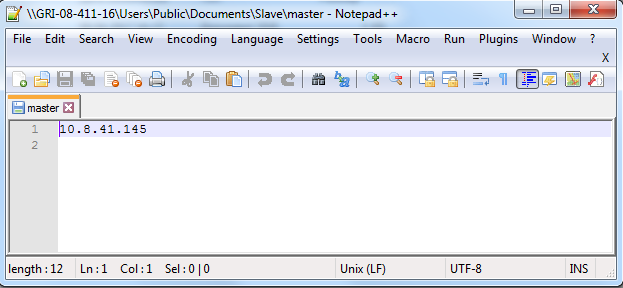
Edit master file in master and slaves machine as follows:
- put IP addresses of master machine
Edit slaves file in master machine as follows:
- put IP addresses of master and slaves node
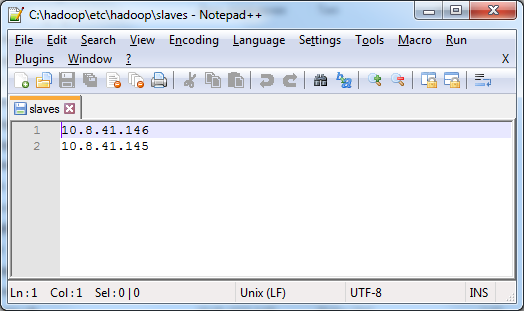
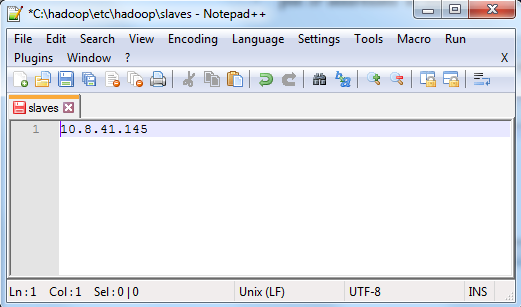
Edit slaves file in slaves' machines as follows:
- put IP addresses of slave node (itself)
B) core-site.xml file
Edit core-site.xml file in master and slaves machine as follows:
- put the IP address of master node and default 9000 port (name node)
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://10.8.41.146:9000</value>
</property>
</configuration>
C) hdfs-site.xml file
- Edit hdfs-site.xml file in master machine as follows:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/data/dfs/datanode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.http.address</name>
<value>127.0.0.1:50070</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<description>to enable webhdfs</description>
<final>true</final>
</property>
</configuration>
- Edit hdfs-site.xml file in slaves machines as follows:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/data/dfs/datanode</value>
</property>
4) Launch Hadoop Deamons
Start Hadoop HDFS by launching Hadoop Deamons on each node in cluster:
Go to the location: “D:\hadoop\sbin” and run the following files as administrator “start-dfs.cmd”
You should see two windows: namenode and datanode
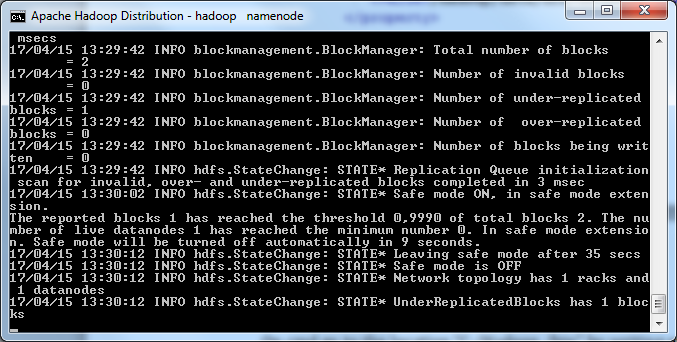
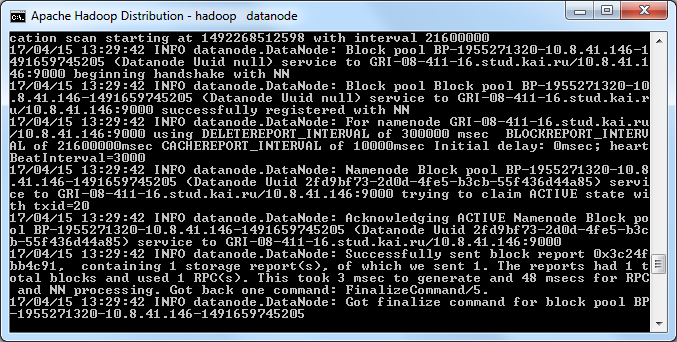
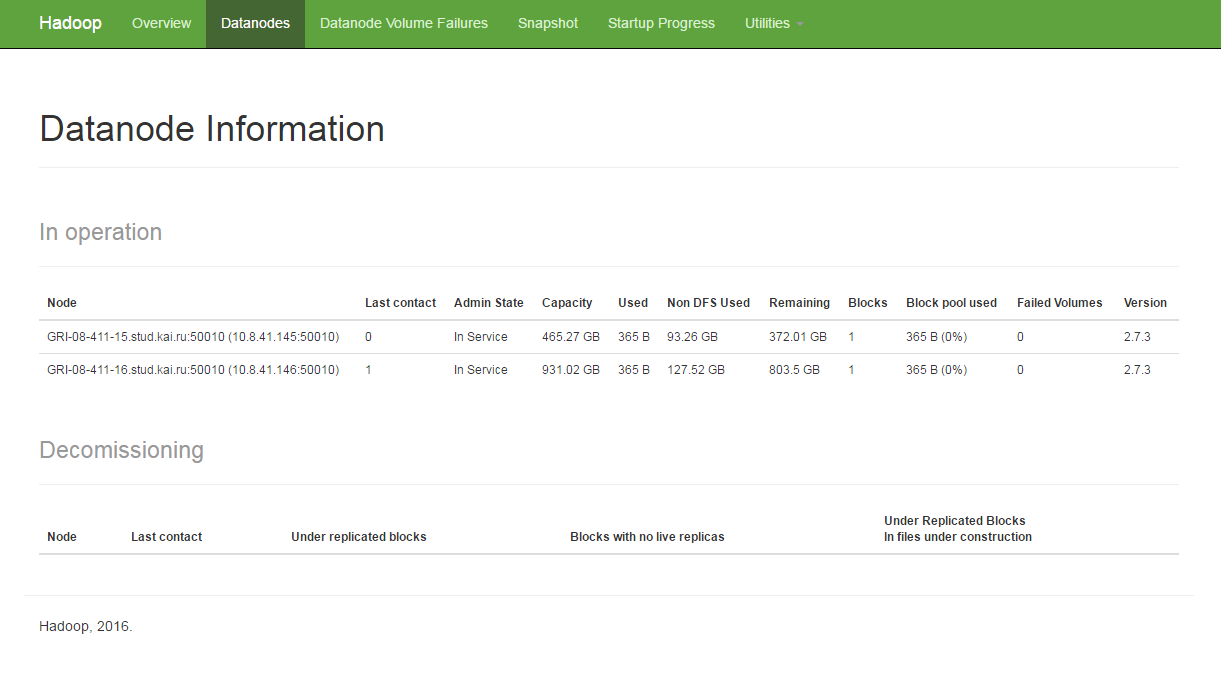
5) Check Hadoop HDFS state via Web UI
Go to web browser http://localhost:50070 (in master node) or http://masterIP:50070 (in slaves) in order to check HDFS state