Apache Spark: Machine Learning with MLlib

Spark MLlib is scalable machine learning library natively supported with Spark, which provides a common machine learning algorithms, such as classification, regression, clustering, collaborative filtering, frequent pattern mining and etc. Spark MLlib focuses on processing data which is presented in RDD, as well as primitive data structures, such vectors and matrices.
MLlib Programming Guide is official Spark MLlib guide.
Dependencies
In order to use Spark MLlib component please provide all needed dependencies for your sbt or maven project.
For example, for maven project pom.xml file will have the following dependencies:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>2.1.0</version>
</dependency>
Spark's DataFrame based API's
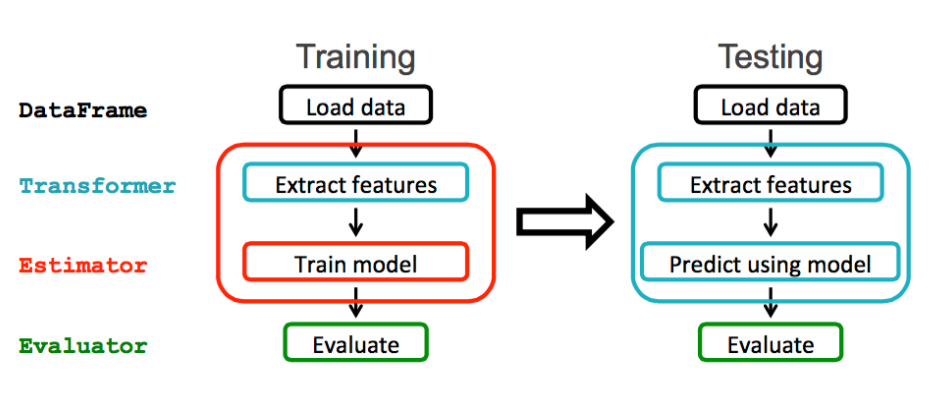
Spark ML provides a uniform set of high-level APIs built on top of DataFrames. The main concepts in Spark ML are:
- DataFrame: The ML API uses DataFrames from Spark SQL as an ML dataset.
- Transformer: A Transformer is an algorithm which transforms one DataFrame into another DataFrame. For example, turning a DataFrame with features into a DataFrame with predictions.
- Estimator: An Estimator is an algorithm which can be fit on a DataFrame to produce a Transformer. For example, training/tuning on a DataFrame and producing a model.
- Pipeline: A Pipeline chains multiple Transformers and Estimators together to specify a ML workflow.
- ParamMaps: Parameters to choose from, sometimes called a “parameter grid” to search over.
- Evaluator: Metric to measure how well a fitted Model does on held-out test data.
- CrossValidator: Identifies the best ParamMap and re-fits the Estimator using the best ParamMap and the entire dataset.
Spark ML workflow shown below [taken from]: