ML Transformers
A transformer is a ML Pipeline component that transforms a DataFrame into another DataFrame.
Examples of transformers are VectorAssembler, StringIndexer, SQLTransformer and so on. The full list of transformers is available on the origin source.
SQLTransformer
implements the transformations which are defined by SQL statement. Currently we only support SQL syntax like
"SELECT ... FROM __THIS__ ..."where "__THIS__"represents the underlying table of the input dataset. The select clause specifies the fields, constants, and expressions to display in the output, and can be any select clause that Spark SQL supports. Users can also use Spark SQL built-in function and UDFs to operate on these selected columns. For example,SQLTransformersupports statements like:
import org.apache.spark.ml.feature.SQLTransformer
val df = spark.createDataFrame(
Seq((0, 1.0, 3.0), (2, 2.0, 5.0))).toDF("id", "v1", "v2")
val sqlTrans = new SQLTransformer().setStatement(
"SELECT *, (v1 + v2) AS v3, (v1 * v2) AS v4 FROM __THIS__")
sqlTrans.transform(df).show()
StringIndexer
StringIndexer encodes a string column of labels to a column of label indices. The indices are in [0, numLabels), ordered by label frequencies, so the most frequent label gets index 0.
In order to apply some MLlib approach you have to represent all categorical features(string values) in numeric form, that is why StringIndexer is needed.
Assume that we have the following dataframe with categorical features:
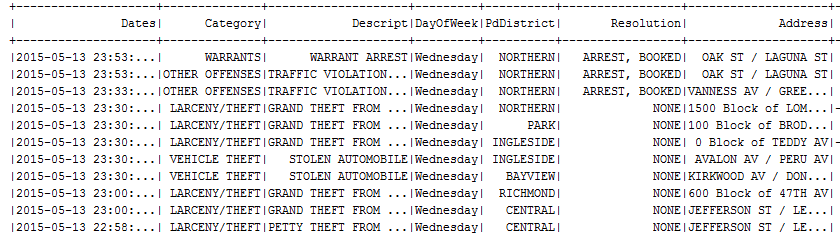 In order to use categorical features in learning algorithms you have to transform them in numeric view:
In order to use categorical features in learning algorithms you have to transform them in numeric view:
var categoryIndex = new StringIndexer()
.setInputCol("Category")
.setOutputCol("CategoryIndex")
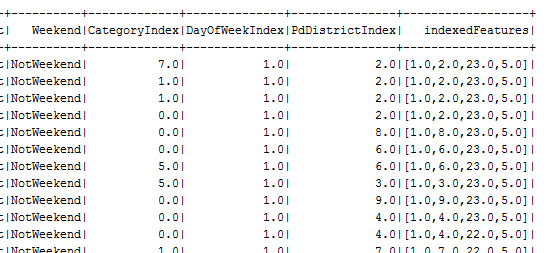
val crimesTransformed = categoryIndex.fit(crimes).transform(crimes)
crimesTransformed.show()
VectorAssembler
VectorAssembler is a feature transformer that assembles (merges) multiple columns into a (feature) vector column.
Example of preparing DataFrame is listed below:
import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler}
import org.apache.spark.ml.tuning.{CrossValidator, ParamGridBuilder}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{udf, _}
object MLPipeline {
def main(args: Array[String]): Unit = {
val inputFile = args(0);
Logger.getLogger("org").setLevel(Level.OFF)
Logger.getLogger("akka").setLevel(Level.OFF)
//Initialize SparkSession
val sparkSession = SparkSession
.builder()
.appName("spark-read-csv")
.master("local[*]")
.getOrCreate();
//Read file to DF
val crimes = sparkSession.read
.option("header", "true")
.option("delimiter", ",")
.option("nullValue", "")
.option("treatEmptyValuesAsNulls", "true")
.option("inferSchema", "true")
.csv(inputFile)
crimes.show(100)
crimes.printSchema();
val dayOrNight = udf {
(h: Int) =>
if (h > 5 && h < 18) {
"Day"
} else {
"Night"
}
}
val weekend = udf {
(day: String) =>
if (day == "Sunday" || day == "Saturday") {
"Weekend"
} else {
"NotWeekend"
}
}
val df = crimes
.withColumn("HourOfDay", hour(col("Dates")))
.withColumn("Month", month(col("Dates")))
.withColumn("Year", year(col("Dates")))
.withColumn("HourOfDay", hour(col("Dates")))
.withColumn("DayOrNight", dayOrNight(col("HourOfDay")))
.withColumn("Weekend", weekend(col("DayOfWeek")))
var categoryIndex = new StringIndexer().setInputCol("Category").setOutputCol("CategoryIndex")
var dayIndex = new StringIndexer().setInputCol("DayOfWeek").setOutputCol("DayOfWeekIndex")
var districtIndex = new StringIndexer().setInputCol("PdDistrict").setOutputCol("PdDistrictIndex")
var dayNightIndex = new StringIndexer().setInputCol("DayOrNight").setOutputCol("DayOrNightsIndex")
val assembler = new VectorAssembler().setInputCols(Array(
"DayOfWeekIndex", "PdDistrictIndex","HourOfDay", "Month"))
.setOutputCol("indexedFeatures")
val pipeline = new Pipeline()
.setStages(Array(categoryIndex, dayIndex, districtIndex, assembler))
val trainDF = pipeline.fit(df).transform(df)
trainDF.show()
}